
1/5/2024 (TinAI.vn) – Theo một phân tích gần đây, 1% bài báo khoa học được xuất bản vào năm 2023 cho thấy dấu hiệu về sự tham gia tiềm năng của AI.
Các nhà nghiên cứu đang lạm dụng ChatGPT và các chatbot trí tuệ nhân tạo khác để tạo ra tài liệu khoa học. Ít nhất, đó là một nỗi e ngại mới mà một số nhà khoa học đã nêu lên, trích dẫn sự gia tăng rõ rệt về số lượng các lỗi AI đáng ngờ xuất hiện trong những bài báo khoa học đã xuất bản.
Một số thông tin có thể minh chứng cho điều này, chẳng hạn như việc vô tình đưa câu “chắc chắn, đây là phần giới thiệu khả thi cho chủ đề của bạn” trong một bài báo gần đây trên Surfaces and Interfaces, một tạp chí do Elsevier xuất bản—là bằng chứng rõ ràng hợp lý cho thấy một nhà khoa học đã sử dụng một chatbot AI. Nhưng “đó có lẽ chỉ là phần nổi của tảng băng trôi,” nhà tư vấn liêm chính khoa học Elisabeth Bik cho biết. (Đại diện của Elsevier nói với Scientific American rằng nhà xuất bản rất tiếc về tình huống này và đang điều tra xem làm thế nào mà họ có thể “vượt qua” quá trình đánh giá bản thảo.) Trong hầu hết các trường hợp khác, sự tham gia của AI không rõ ràng và trình phát hiện văn bản AI tự động là những công cụ không đáng tin cậy để phân tích một bài báo.
Tuy nhiên, các nhà nghiên cứu từ một số lĩnh vực đã xác định được một số từ và cụm từ chính (chẳng hạn như “ phức tạp và nhiều mặt ”) có xu hướng xuất hiện thường xuyên hơn trong các câu do AI tạo ra hơn là trong văn bản thông thường của con người. Andrew Gray, thủ thư và nhà nghiên cứu tại Đại học College London, cho biết: “Khi bạn nhìn những thứ này đủ lâu, bạn sẽ cảm nhận được phong cách của nó.
Mô hình ngôn ngữ lớn – Large language model (LLM) được thiết kế để tạo ra văn bản nhưng những gì chúng tạo ra có thể chính xác hoặc không chính xác về mặt thực tế. Bik nói: “Vấn đề là những công cụ này chưa đủ tốt để được tin cậy”. Họ không chịu nổi thứ mà các nhà khoa học máy tính gọi là ảo giác: nói một cách đơn giản, nó có thể bịa ra mọi thứ. “Đặc biệt, đối với các bài báo khoa học,” Bik lưu ý, AI “sẽ tạo ra các tài liệu tham khảo trích dẫn không tồn tại.” Vì vậy, nếu các nhà khoa học đặt quá nhiều niềm tin vào LLM, các tác giả nghiên cứu có nguy cơ đưa ra các dẫn chứng sai sót do AI tạo ra và đưa vào công trình của họ.
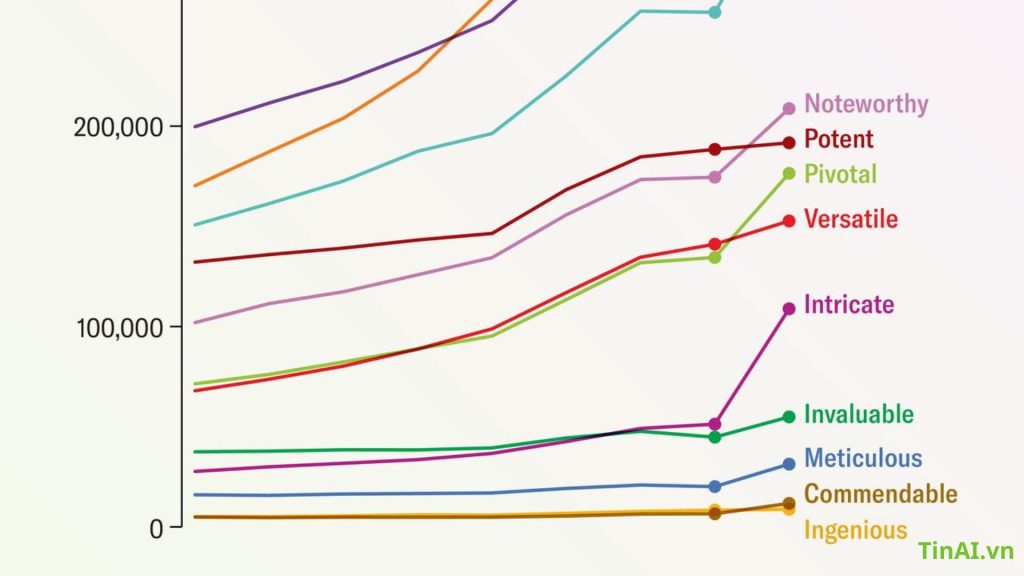
Gray gần đây đã săn lùng các từ thông dụng AI trong các bài báo khoa học bằng cách sử dụng Dimensions, một nền tảng phân tích dữ liệu mà các nhà phát triển của nó cho biết đã theo dõi hơn 140 triệu bài báo trên toàn thế giới. Anh ấy đã tìm kiếm những từ được chatbot sử dụng thường xuyên, chẳng hạn như “phức tạp”, “tỉ mỉ” và “đáng khen ngợi”. Ông nói, những từ chỉ báo này giúp nhận biết một tác giả vụng về nào đó có thể sao chép vào một bài báo. Theo phân tích của Gray, ít nhất 60.000 bài báo—hơn 1% tổng số bài báo khoa học được xuất bản trên toàn cầu vào năm ngoái—có thể đã sử dụng LLM, theo phân tích của Gray , được phát hành trên máy chủ in sẵn arXiv.org và vẫn chưa được bình duyệt. Một cuộc điều tra khác gần đây còn cho thấy có tới 17,5% các bài báo khoa học máy tính có dấu hiệu viết bằng AI.
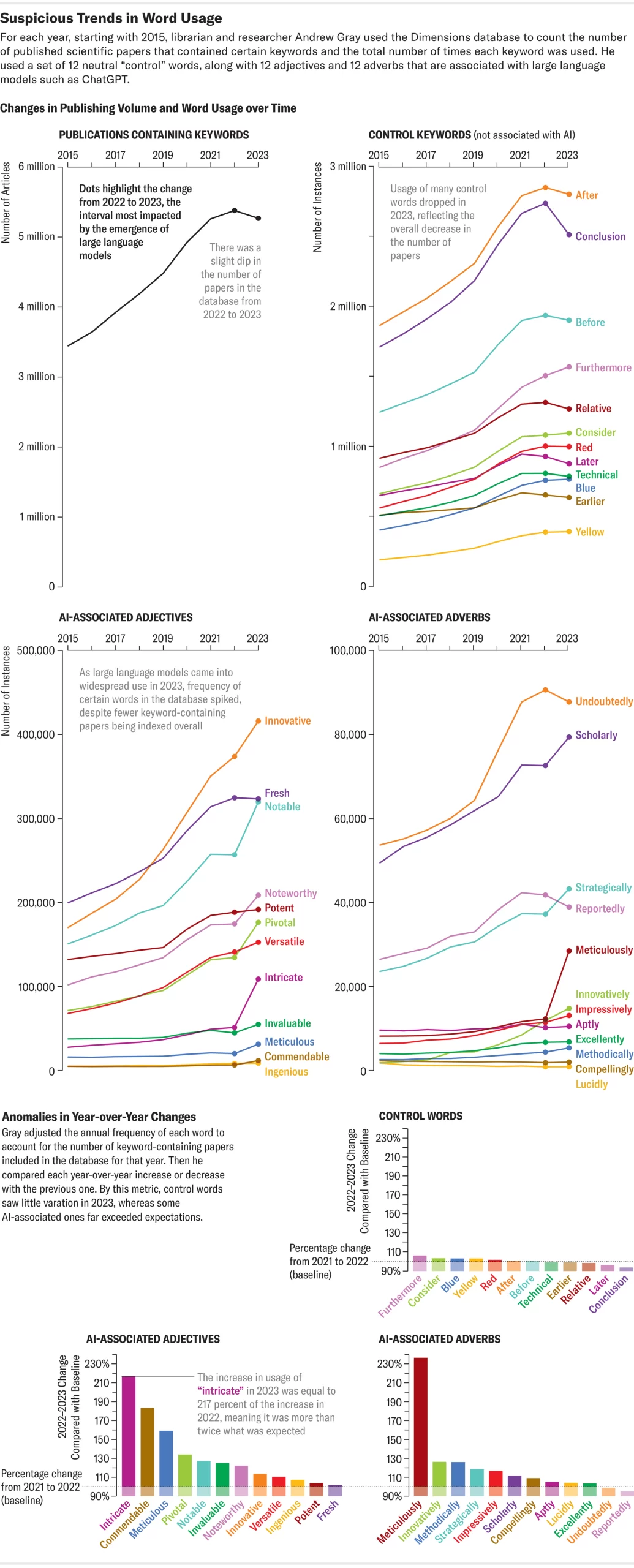
Những phát hiện này được hỗ trợ bởi tìm kiếm riêng của Scientific American bằng Dimensions và một số cơ sở dữ liệu xuất bản khoa học, bao gồm Google Scholar, Scopus, PubMed, OpenAlex và Internet Archive Scholar. Tìm kiếm này xác định các dấu hiệu có thể gợi ý LLM có liên quan đến việc tạo văn bản cho các bài báo học thuật — được đo bằng mức độ phổ biến của các cụm từ mà ChatGPT và các mô hình AI khác thường thêm vào, chẳng hạn như “kể từ lần cập nhật kiến thức cuối cùng của tôi”. Vào năm 2020, cụm từ đó chỉ xuất hiện một lần trong kết quả được theo dõi bởi bốn nền tảng phân tích bài báo chính được sử dụng trong cuộc điều tra. Nhưng nó đã xuất hiện 136 lần vào năm 2022. Tuy nhiên, có một số hạn chế đối với phương pháp này: Nó không thể lọc ra các bài báo có thể trình bày các nghiên cứu về chính mô hình AI hơn là nội dung do AI tạo ra. Và những cơ sở dữ liệu này bao gồm các tài liệu nằm ngoài các bài báo được bình duyệt trên các tạp chí khoa học.
Giống như cách tiếp cận của Gray, tìm kiếm này cũng đưa ra những dấu vết tinh vi hơn có thể hướng tới LLM: nó xem xét số lần các cụm từ hoặc từ phổ biến ChatGPT ưa thích được tìm thấy trong tài liệu khoa học và theo dõi xem mức độ phổ biến của chúng có khác biệt đáng kể trong những năm qua hay không. Ngay trước khi phát hành chatbot của OpenAI vào tháng 11 năm 2022 (quay trở lại năm 2020). Các phát hiện này cho thấy có điều gì đó đã thay đổi trong từ vựng của văn bản khoa học – một sự phát triển có thể là do thói quen viết của các chatbot ngày càng hiện diện nhiều hơn đã tạo ra. “Có một số bằng chứng cho thấy một số từ thay đổi đều đặn theo thời gian” khi ngôn ngữ phát triển bình thường, Gray nói. “Nhưng có một câu hỏi đặt ra là bao nhiêu trong số này là sự thay đổi ngôn ngữ tự nhiên và bao nhiêu là có điều gì đó khác biệt.”
Sự ảnh hưởng của Chatbot AI
Đối với các dấu hiệu cho thấy AI có thể tham gia vào quá trình sản xuất hoặc chỉnh sửa các bài báo khoa học, tìm kiếm của Scientific American đã đi sâu vào từ “đi sâu” – như một số người giám sát không chính thức về văn bản do AI tạo ra đã chỉ ra, chứng kiến sự gia tăng bất thường trong việc sử dụng của giới học thuật. Một phân tích về việc sử dụng nó trong khoảng 37 triệu trích dẫn và tóm tắt bài báo về khoa học đời sống và y sinh có trong danh mục PubMed đã nêu bật mức độ thịnh hành của từ này. Tăng từ 349 lượt sử dụng vào năm 2020, “delve” xuất hiện 2.847 lần vào năm 2023 và đã tăng 2.630 lần cho đến năm 2024—tăng 654%. Sự gia tăng tương tự nhưng ít rõ rệt hơn đã được thấy trong cơ sở dữ liệu Scopus, bao gồm phạm vi khoa học rộng hơn và trong dữ liệu Thứ nguyên.

Theo phân tích của Scientific American, các thuật ngữ khác được các nhà giám sát này gắn cờ là từ khóa do AI tạo ra cũng có mức tăng tương tự : “đáng khen ngợi” xuất hiện 240 lần trong các bài báo do Scopus theo dõi và 10.977 lần trong các bài báo do Dimensions theo dõi vào năm 2020. Những con số đó tăng vọt lên 829 (tăng 245 phần trăm) và 20.536 (tăng 87 phần trăm), tương ứng, vào năm 2023. Và có lẽ đó là một bước ngoặt mỉa mai đối với việc nghiên cứu đáng lẽ phải là “tỉ mỉ”, từ đó đã tăng gấp đôi trên Scopus trong khoảng thời gian từ năm 2020 đến năm 2023.
Trong một thế giới nơi các học giả tuân theo nguyên tắc “ xuất bản hoặc diệt vong ”, không có gì phải ngạc nhiên khi một số người đang sử dụng chatbot để tiết kiệm thời gian hoặc củng cố khả năng sử dụng tiếng Anh của họ trong một lĩnh vực thường được yêu cầu xuất bản đòi hỏi sự chính xác trong việc trình bày về ngữ pháp, chính tả đối với những tác giả không có tiếng mẹ đẻ khôn phải là tiếng Anh. Nhưng việc sử dụng công nghệ AI làm công cụ trợ giúp ngữ pháp hoặc cú pháp có thể dẫn đến việc áp dụng sai công nghệ này trong các phần khác của quy trình khoa học như đưa ra các bộ số liệu hoặc những phân tích không chính xác hoặc kết luận không có căn cứ.
Đây không phải là những kịch bản giả thuyết thuần túy. AI chắc chắn đã được sử dụng để tạo ra các sơ đồ và hình minh họa khoa học thường được đưa vào các bài báo học thuật và thậm chí còn có thể thay thế những người tham gia thí nghiệm là con người . Và việc sử dụng chatbot AI có thể đã thâm nhập vào chính quá trình đánh giá các bài báo khoa học dựa trên một nghiên cứu in sẵn về ngôn ngữ trong phản hồi được cung cấp cho các nhà khoa học trình bày nghiên cứu tại các hội nghị về AI vào năm 2023 và 2024. Nếu các đánh giá do AI tạo ra lọt vào các bài báo học thuật cùng với văn bản AI, điều đó liên quan đến các chuyên gia, bao gồm Matt Hodgkinson, thành viên hội đồng của Ủy ban Đạo đức Xuất bản, một tổ chức phi lợi nhuận có trụ sở tại Vương quốc Anh nhằm thúc đẩy các hoạt động nghiên cứu học thuật có đạo đức. Ông nói, chatbot “không giỏi phân tích và đó là điểm nguy hiểm thực sự”.
Trung Kiên
(Theo CHRIS STOKEL-WALKER – Scientific American)