
28/6/2024 (TinAI.vn) – Gemma 2 của Google là một mô hình AI ngôn ngữ mã nguồn mở cung cấp hiệu suất tốt nhất, chạy ở tốc độ đáng kinh ngạc trên các phần cứng khác nhau và dễ dàng tích hợp với các công cụ AI khác chính thức được công bố ra mắt ngày hôm qua.
Gemma 2 được cung cấp với 2 phiên bản có tham số 9 tỷ (9B) và 27 tỷ (27B) Gemma 2 có hiệu suất cao hơn và hiệu quả hơn trong suy luận so với thế hệ đầu tiên, với những tiến bộ đáng kể về an toàn được tích hợp sẵn. Trên thực tế, ở 27B, nó cung cấp các giải pháp thay thế cạnh tranh cho các mô hình có kích thước lớn gấp đôi, mang lại loại hiệu suất mà chỉ có thể đạt được với các mô hình phải trả phí gần đây nhất là vào tháng 12. Và giờ đây có thể đạt được trên một GPU NVIDIA H100 Tensor Core hoặc máy chủ TPU, giúp giảm đáng kể chi phí triển khai.
Một tiêu chuẩn mô hình mở mới cho hiệu quả và hiệu suất
Google đã xây dựng Gemma 2 trên kiến trúc được thiết kế lại để mang lại cả hiệu suất vượt trội và hiệu quả suy luận. Một số điểm nổi bật của Gemma 2:
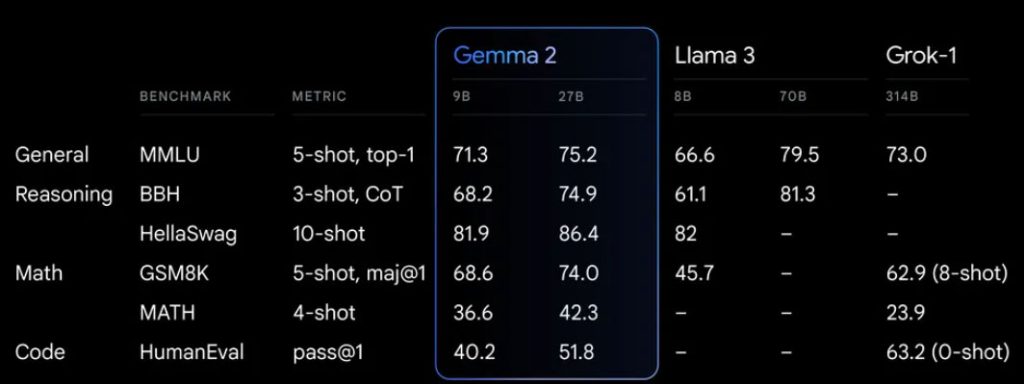
- Hiệu suất vượt trội: Với Model 27B, Gemma 2 mang lại hiệu suất tốt nhất cho phân khúc kích thước của nó, và thậm chí còn cung cấp các lựa chọn thay thế cạnh tranh cho các mẫu có kích thước lớn hơn gấp đôi. Model Gemma 2 9B cũng mang lại hiệu suất hàng đầu, vượt trội hơn Llama 3 8B và các mô hình AI mở khác trong phân khúc kích thước của nó. Để biết thông tin chi tiết về hiệu suất, hãy xem báo cáo kỹ thuật .
- Hiệu quả và tiết kiệm chi phí chưa từng có: Mẫu 27B Gemma 2 được thiết kế để chạy suy luận hiệu quả với độ chính xác tối đa trên một máy chủ Google Cloud TPU, GPU NVIDIA A100 80GB Tensor Core hoặc GPU NVIDIA H100 Tensor Core , giúp giảm đáng kể chi phí trong khi vẫn duy trì hiệu suất cao. Điều này cho phép triển khai AI dễ tiếp cận hơn và thân thiện với ngân sách hơn.
- Suy luận cực nhanh trên phần cứng: Gemma 2 được tối ưu hóa để chạy ở tốc độ đáng kinh ngạc trên nhiều loại phần cứng, từ máy tính xách tay chơi game mạnh mẽ và máy tính để bàn cao cấp đến các thiết lập dựa trên đám mây. Hãy thử Gemma 2 với độ chính xác tuyệt đối trong Google AI Studio , mở khóa hiệu suất cục bộ với phiên bản lượng tử hóa với Gemma.cpp trên CPU của bạn hoặc thử trên máy tính tại nhà của bạn với NVIDIA RTX hoặc GeForce RTX thông qua Hugging Face Transformers.
Xây dựng cho các nhà phát triển và nhà nghiên cứu
Gemma 2 không chỉ mạnh mẽ hơn mà còn được thiết kế để tích hợp dễ dàng hơn vào quy trình làm việc của bạn:
- Mở và dễ tiếp cận: Giống như các mô hình Gemma ban đầu, Gemma 2 có sẵn theo giấy phép Gemma cho phép khả năng thương mại, mang lại cho các nhà phát triển và nhà nghiên cứu khả năng chia sẻ và thương mại hóa những sản phẩm của họ.
- Khả năng tương thích với nhiều nền tảng: Dễ dàng sử dụng Gemma 2 với các công cụ và quy trình làm việc ưa thích của bạn nhờ khả năng tương thích với các nền tảng hỗ trợ AI chính như Hugging Face Transformers và JAX, PyTorch và TensorFlow thông qua Keras 3.0, vLLM, Gemma.cpp , Llama.cpp và Ollama gốc . Ngoài ra, Gemma được tối ưu hóa với NVIDIA TensorRT-LLM để chạy trên cơ sở hạ tầng được NVIDIA tăng tốc hoặc như một dịch vụ vi mô suy luận NVIDIA NIM , với khả năng tối ưu hóa cho NeMo của NVIDIA sắp ra mắt. Bạn có thể tinh chỉnh ngay hôm nay với Keras và Hugging Face. Google đang tích cực làm việc để kích hoạt các tùy chọn tinh chỉnh hiệu quả về tham số bổ sung.
- Triển khai dễ dàng: Bắt đầu từ tháng tới, khách hàng của Google Cloud sẽ có thể dễ dàng triển khai và quản lý Gemma 2 trên Vertex AI .
Phát triển AI có trách nhiệm
Google cam kết cung cấp cho các nhà phát triển và nhà nghiên cứu những tài nguyên họ cần để xây dựng và triển khai AI một cách có trách nhiệm, bao gồm cả thông qua Bộ công cụ AI sáng tạo có trách nhiệm . Bộ so sánh LLM mã nguồn mở gần đây giúp các nhà phát triển và nhà nghiên cứu đánh giá chuyên sâu về các mô hình ngôn ngữ. Bắt đầu từ hôm nay, bạn có thể sử dụng thư viện Python đồng hành để chạy các đánh giá so sánh với mô hình và dữ liệu của mình, đồng thời trực quan hóa kết quả trong ứng dụng. Ngoài ra, Google đang tích cực làm việc để tìm nguồn mở cho công nghệ tạo hình mờ văn bản của mình, SynthID , cho các mẫu Gemma.
Khi đào tạo Gemma 2, Google đã tuân theo các quy trình an toàn nội bộ mạnh mẽ của mình, lọc dữ liệu đào tạo trước và thực hiện thử nghiệm và đánh giá nghiêm ngặt theo một bộ số liệu toàn diện để xác định và giảm thiểu các sai lệch và rủi ro tiềm ẩn.
Phương Uyên